xgboost를 파이썬을 적용할 때 두가지 방법이 존재한다.
파이썬 래퍼 XGBoost를 사용하거나 사이킷런 래퍼 XGBoost를 사용하는 것이다.
먼저, 사이킷런에 내장되어 있는 위스콘신 유방암 데이터 세트를 이용하여 파이썬 래퍼 xgboost 실습을 진행해보도록 하겠다. 파이썬 래퍼 xgboost는 자체적으로 교차 검증, 성능 평가, 피처 중요도 등의 시각화 기능을 가지고 있다.
또한, 조기 중단이라는 기능도 가지고 있기에 부스팅 반복 횟수가 끝까지 도달하지 않더라도 예측 성능이 좋아지지 않으면 자체적으로 중지시켜 비교적 빠른 수행시간으로 결과값을 도출할 수 있다.
- 위스콘신 유방암 데이터 예측
위스콘신 유방암 데이터 세트는 종양의 크기, 모양 등의 다양한 속성값을 기반으로 악성 종양(malignant tumor)인지 양성 종양(benign tumor)인지를 예측한다.
양성 종양은 쉽게 전이 되지 않고 성장속도가 느린 반면에 악성 종양은 주위 조직에 빠르게 침입하여 성장하는 종양이다.
- 데이터 / 필요한 라이브러리 불러오기
import xgboost as xgb
from xgboost import plot_importance
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import warnings
dataset = load_breast_cancer()
features = dataset.data
labels = dataset.target
cancer_df = pd.DataFrame(data = features, columns = dataset.feature_names)
cancer_df['target'] = labels
cancer_df.head(3)
사이킷런에 내제되어 있는 breast_cancer 데이터를 불러와 주고, dataset 변수에 load 해 주었다.
내제되어 있는 데이터 셋은 독립변수에 해당하는 data와 종속변수에 해당하는 target이 별개로 되어져 있기 때문에 각각 features와 labels로 저장시켜주고, features를 이용한 데이터 프레임 생성에 labels를 target으로 된 열로 추가해주었다.
- 데이터 확인하기
1. target 값 확인하기
악성종양인지 양성종양인지 예측하기 위한 변수인 target열의 value_counts()를 확인해 보았다.
print(dataset.target_names)
print(cancer_df['target'].value_counts())
결론적으로, 1(악성)값이 357개, 0(양성)값이 212개로 분포되어져 있고, int형인 것을 확인할 수 있다.
2. 데이터 행과 열 갯수 파악하기
cancer_df.shape
# (569,31)데이터는 569개의 행과 31개의 열로 구성되어져 있다.
3. 데이터 열 종류 확인하기
cancer_df.columns
각각의 열의 의미를 이해하고 싶어서 구글 번역기를 돌려보았다.
- radius : 반지름, 반경
- texture : 조직, 질감
- perimeter : 둘레
- area : 영역
- smoothness : 매끄러움, 부드러움
- compactness : 조밀함, 압축
- concavity : 오목한
- concave points : 오목한 점
- symmetry : 대칭
- fractal dimension : 프렉탈 차원 ( 프렉탈* : 임의의 한 부분이 전체의 형태와 닮은 도형 )
일단 이 단어들의 의미만 알면 앞에 붙는 mean(평균), error(오차), worst(최악)에 따라서 의미가 변경된다는 것을 알 수 있었다.
4. 데이터 정보 확인하기
cancer_df.info()
위의 결과를 보면, 결측치가 존재하는 열이 없다. 또, 30개의 float(실수)형과 1개의 int(정수)형이 존재한다.
행이 569개인 것으로 볼 때, 데이터 양이 그렇게 크지 않다는 것을 알 수 있다.
- train / validation / test 데이터 셋으로 나누기
모델을 학습하기 전에 원본 데이터 셋을 train, validation, test 데이터 셋으로 분할하였다.
여기서 검증용 데이터를 분리한 이유는, XGBoost가 제공하는 기능인 검증 성능 평가와 조기중단을 수행하기 위해서이다.
# cancer_df에서 feature용 DataFrame과 Label용 Series 객체 추출
# 맨 마지막 칼럼이 label이기 때문에 슬라이싱으로 추출
X_features = cancer_df.iloc[:,:-1]
y_label = cancer_df.iloc[:,-1]
# 전체 데이터셋에서 80%는 학습용 데이터, 20%는 테스트용 데이터로 추출
X_train, X_test, y_train, y_test = train_test_split(X_features, y_label, test_size = 0.2, random_state = 156)
# 위에서 만든 train, test 데이터를 다시 쪼개서 90%는 학습, 10%는 검증용 데이터로 추출
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train, test_size = 0.1, random_state = 156)
print(X_train.shape, X_test.shape)
print(X_tr.shape, X_val.shape)
위의 결과에 따라서 최종 학습용 데이터는 409개, 검증용 데이터는 46개, 테스트용 데이터는 114개로 나누어진 것을 확인할 수 있다.
파이썬 래퍼 XGBoost는 사이킷런 래퍼와 여러가지 차이점이 있지만, 그 중에서도 pandas, numpy 형태로 되어 있는 데이터를 DMatrix 형태로 변환하여 사용하는 차이점이 존재한다.
DMatrix 형태로 변환해주기 위해서는 data와 label 값을 지정해 주어야 한다.
# 파이썬 래퍼 XGBoost는 데이터 형태를 DMatrix로 변환해주어야 함
dtr= xgb.DMatrix(data = X_tr, label = y_tr)
dval = xgb.DMatrix(data = X_val, label = y_val)
dtest = xgb.DMatrix(data = X_test, label = y_test)
- XGBoost 하이퍼 파라미터 지정하기
- max_depth : 트리의 최대 깊이
- eta : learning_rate (학습률)
- objective : 목적함수 , 이진분류이기 때문에 binary:logistic으로 지정
- eval_metric : 성능평가 지표 (logloss) , 분류 데이터에서는 주로 error과 logloss 사
- num_rounds : 부스팅 반복 횟수 (조기중단 기능에 따라서 지정된 횟수로 반복을 하지 않고 중간에 빠져나올 수 있음)
# XGBoost 하이퍼 파라미터 지정하기
params = {'max_depth' : 3,
'eta' : 0.05,
'objective' : 'binary:logistic',
'eval_metric':'logloss'}
num_rounds = 400
XGBoost의 조기 중단 성능 평가는 주로 별도의 검증 데이터 세트를 이용한다. (위에서 검증 데이터를 나누어준 이유)
조기 중단 파라미터는 early_stopping_rounds이고, 여기서는 50으로 설정해주었다.
조기중단을 실행하기 위해서는 반드시 평가용 데이터 세트 지정과 eval_metric을 함께 설정해주어야 한다 !
평가용 데이터 세트는 아래 코드와 같이 학습과 평가용 데이터 세트를 명기하는 개별 튜플을 가지는 리스트 형태로
설정해야 한다.
# 학습 데이터 셋은 'train' , 평가용 데이터 셋은 'eval'로 명기한다.
eval_list = [(dtr,'train'),(dval,'eval')]
# 또는 eval_list = [(dval,'eval')]만 명기해도 무방
# 하이퍼 파라미터와 early_stopping 파라미터를 train() 함수의 파라미터로 전달
xgb_model = xgb.train(params = params, dtrain = dtr, num_boost_round = num_rounds,
early_stopping_rounds = 50, evals = eval_list)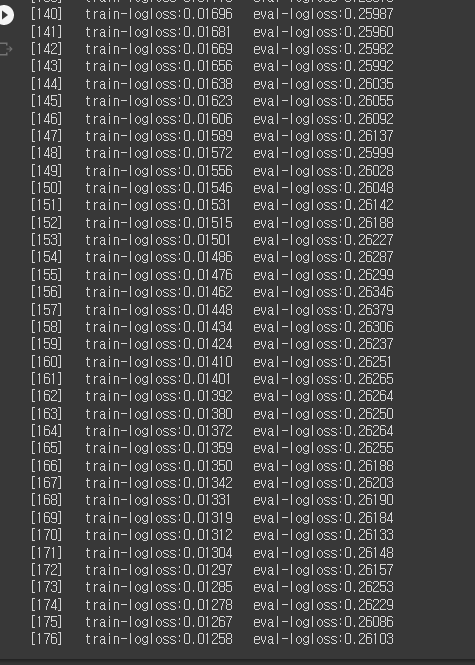
위의 결과를 통해서 train-logloss와 eval-logloss가 지속적으로 감소하고 있음을 알 수 있다.
또, num_boost_rounds 파라미터를 400으로 지정했음에도 불구하고 176에서 조기중단한 것을 볼 수 있다.
이는, 126번째 반복에서 0.25587로 가장 낮고 (logloss 값이 작을수록 모델의 성능이 좋다는 의미), 이후로 더 향상된 값이 50회 반복한 결과 없기 때문에 조기 중단 기능이 수행된 것이다.

xgboost를 이용해 학습을 완료했기에 이를 테스트 데이터 세트에서 예측을 수행해 보았다.
파이썬 래퍼 XGBoost는 train() 함수를 호출해 학습이 완료된 모델 객체를 반환하게 되는데, 이 모델 객체는 예측을 위해 predict() 메서드를 이용한다.
여기서 사이킷런 래퍼 XGBoost의 predict() 메서드는 예측결과를 클래스로 반환하는데에 반해,
파이썬 래퍼 XGBoost의 predict() 메서드는 예측 결과값이 아닌 예측 결과를 추정할 수 있는 확률 값을 반환한다.
pred_probs = xgb_model.predict(dtest)
print('predict() 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨')
# 소수점 3번째까지만 보여주는 코드
print(np.round(pred_probs[:10],3))
# 예측 확률이 0.5보다 크면 1, 그렇지 않으면 0으로 예측값을 결정하여 list 객체인 preds에 저장됨
preds = [1 if x > 0.5 else 0 for x in pred_probs]
print('예측값 10개만 표시 :', preds[:10])
다음으로 이렇게 예측된 preds와 실제 값인 y_test를 인자로 입력하여 정확도, 정밀도, 재현율을 구해보았다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
# 정확도, 정밀도, 재현율, 오차행렬을 출력해주는 함수 생성
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
print('오차행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}'.format(accuracy, precision, recall))
get_clf_eval(y_test,preds)
- 변수중요도 확인
마지막으로 xgboost의 내장된 시각화 기능을 수행하여 변수 중요도를 확인해 보았다.
plot_importance(xgb_model)
'Data Analysis > Python' 카테고리의 다른 글
| Light GBM에 관하여 (0) | 2023.03.05 |
|---|---|
| 사이킷런 래퍼 XGBoost (0) | 2023.03.05 |
| XGBoost_하이퍼파라미터 (0) | 2023.02.28 |
| 분류_GBM(Gradient Boost Machine) (0) | 2023.02.01 |
| 분류_앙상블 학습 (0) | 2023.02.01 |



