1. Applying the Model
먼저 , 분석하고자 하는 데이터 셋을 불러와준다.

데이터를 불러와줄 때, 예측하고 싶은 열을 label로 지정해준다.
label로 지정해주면 다음과 같이 색이 다르게 보여진다.
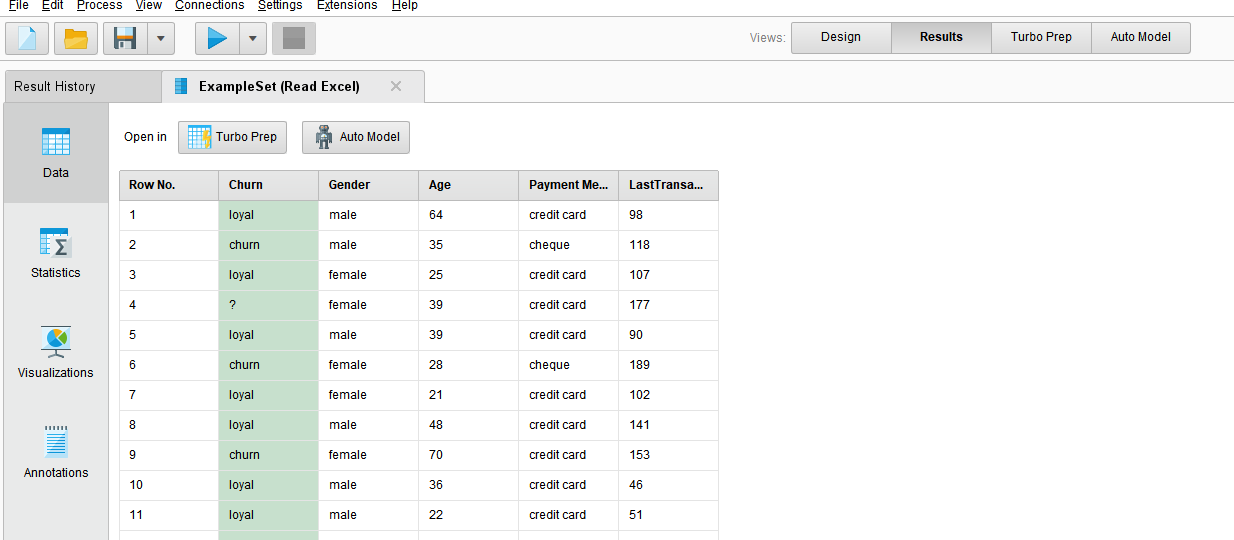
예측하고자 하는 열이 Churn인데, 여기서 missing value가 보여진다. (96개)

이를 제거해주기 위해서 filter examples 오피레이터를 이용해서 해당 열을 is not missing으로 설정해준다.

그럼, 다음과 같이 결측치가 사라진 것을 확인할 수 있다.

그런 다음, Decision Tree 모델을 설정해주고, 앞서 해준 filter examples를 한번 더 해준다.

다음, apply model을 지정해주는데, 여기서 mod이라고 적힌 곳에 사용하고자 하는 모델인 Decision Tree를 지정하고, uni에는 데이터 셋인 filter example 해준 데이터를 연결해주고 실행시켜준다.

결과를 확인해보면 사용한 모델인 의사결정나무가 구축된 것을 시각적으로 볼 수 있고, 모델을 사용해서 예측한 결과도 확인할 수 있다.


-> 이처럼 apply 모델을 사용해서 데이터를 예측하는 모델을 실행시켜 줄 수 있는 기능이다.
2. Testing a Model
앞서 apply 모델을 진행한 곳에서 performance 오피레이터를 추가해준다.
여기서 주의할 점은, 분류인지, 회귀인지 생각해야 한다.
사용한 데이터에 따라서 숫자를 예측하는 회귀인지, 카테고리를 분류하는 분류모델인지에 따라서 performance 오피레이터의 구성이 달라진다.
내가 사용한 데이터는 분류였기 때문에 performance(classification)을 사용해주었다.

분류모델은 주로, 정확도(accuracy), 재현율(recall), 정밀도(precision), f1score를 확인하여 사용해도 괜찮은 모델인지 판단해준다.
여기서는 accuracy 성능지표를 통해서 87%에 해당하는 좋은 성능을 보인 것을 확인해줄 수 있었다.

3. Validating a Model
모델을 사용해서 종속변수를 예측해 줄 때, 데이터 셋을 나누어주어야 한다.
훈련 데이터 셋, 테스트 데이터 셋으로 나누는 것이 일반적인데, 여기서는 교차검증에 대해서 설명하고자 한다.
교차검증은 데이터를 훈련, 검증, 테스트 데이터, 총 3개로 나누어서 훈련을 진행한다.
아래에 보이는 그림과 같이 k갯수를 정해서 k번 나누어 교차검증을 진행하는데, train으로 나누어준 데이터 셋에서 다시 비율에 맞게 검증데이터와 훈련 데이터로 나누어준다.
아래는 5번으로 나누어서 검증을 진행해 주었고, 각각 iteration에 대한 값을 평균을 구해서 최종적인 값을 구한다.

실습을 진행해주기 위해서 위의 데이터와 같은 데이터를 불러와주고, 종속변수인 Churn 열의 결측치를 제거해준다.


crossvalidation 오피레이터를 사용해서 교차검증을 진행해준다.

cross validation을 두번 클릭해주면, 아래와 같이 training과 testing으로 나뉘어진 화면을 볼 수 있고,
앞서 배운 모델, apply model 오피레이터, performance 오피레이터를 불러와서 연결해준다.

그런 뒤, cross validatio 오피레이터의 mod와 per를 연결해주어야 사용한 모델과 그에 대한 성능을 볼 수 있다.

최종적인 결과를 확인해보면 82%의 정확도를 보여주는 것을 알 수 있다.

'Data Analysis > RapidMiner' 카테고리의 다른 글
| [Altair 래피드마이너 서포터즈] 6회차 활동 (1) | 2023.05.14 |
|---|---|
| [Altair 래피드마이너 서포터즈] 5회차 활동 (0) | 2023.05.04 |
| [Altair 래피드마이너 서포터즈] 4회차 활동 (0) | 2023.04.16 |
| [Alter 래피드마이너 서포터즈] 3회차 활동 (0) | 2023.03.28 |
| [Alter 래피드마이너 서포터즈] 2회차 활동 (0) | 2023.03.10 |



