
데이터 분석과 관련된 공부를 하고 있는 사람들은 캐글(Kaggle)이라는 사이트를 알고 있을 것이라 생각한다.
캐글(Kaggle) 사이트는 세계적인 머신러닝 기반 분석 대회가 열리고 있는 대표적인 온라인 포털 사이트이다.
처음 데이터 분석에 접할 때 가장 많이 사용하는 데이터 셋이 타이타닉 생존자 예측 분석이라고 해도 될 만큼 기초적인 데이터 분석 사례이다.
나도 분석을 처음 공부 할 때 타이타닉 생존자 예측 분석을 진행했었다.
그 때 당시에는 데이터 불러오는 것조차 어려워했었던 감자였는데 반복적으로 분석을 공부하다 보니 조금은 쉬워진 것 같다.
이번에는 사이킷런을 이용하여 타이타닉 생존자 예측 분석을 진행할 것이다.
먼저, 데이터 셋에 존재하는 열들에 대해 각각 이해하고 넘어가자.
- PassengerID : 승객들 번호
- Survived : 생존 여부 (0 : 생존x , 1 : 생존0)
- Pclass : 티켓의 선실 등급 ( 1 : 일등석, 2 : 이등석, 3 : 삼등석)
- Sex : 탑승자 성별
- Name : 탑승자 이름
- Age : 탑승자의 나이
- Sibsp : 같이 탑승한 형제자매 또는 배우자 인원수
- Parch : 같이 탑승한 부모님 또는 자녀 인원수
- Ticket : 티켓번호
- Fare : 요금
- Cabin : 선실 번호
- Embarked : 중간 정착 항구 (C = Cherbourg, Q = Queenstown, S = Southampton)
1. 데이터 및 필요한 라이브러리 불러오기
- 분석을 하는 데 필요한 라이브러리를 불러온다. 이번에는 시각화도 같이 진행할 것이기 때문에 그에 맞는 matplotlib.pyplot과 seaborn도 불러온다.
- head() 함수를 사용하여 보고 싶은 행의 숫자만큼 데이터를 볼 수 있다.

2. 데이터 탐색
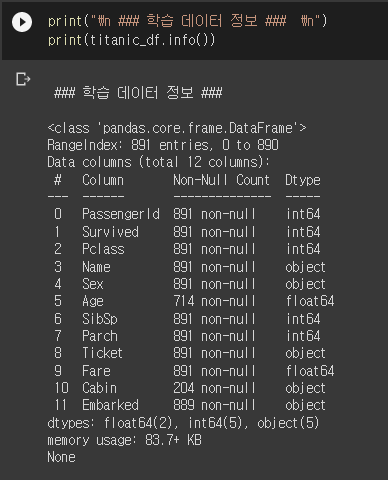
- 데이터가 어떻게 구성되어 있는지 알아보기 위해 info() 함수를 사용해주었다.
- 이 외에도 shape, describe(), isnull().sum() 을 활용하여 더 자세한 정보를 알 수 있다.
- 밑의 정보를 보면 총 891개의 행으로 구성되어져 있는데, Age, Cabin, Embarked 열에서 결측치가 존재한다는 것을 알 수 있다.
3. 결측치 처리
- 앞서 확인했던 결측치들을 처리한다. 처리하는 방법에는 대표적으로 제거하는 것과 채워넣어주는 법이 존재한다.
- Age 열의 결측치는 mean() 함수를 사용하여 평균값으로 대체해준다.
- Cabin과 Embarked는 문자열 열이기 때문에 "N" 값으로 채워넣어준다.
- 최종적으로 결측치의 갯수를 확인하기 위해서 isnull().sum().sum() 함수를 통해 알아본 결과 결측치가 없다고 확인되었다.

4. 문자열 변수 확인하기
- 문자열 변수(범주형 변수)에는 Sex, Cabin, Embarked 열이 있다.
- 각 변수에 대하여 value_counts()로 어떤 값들이 있는지와 몇개가 있는지 확인할 수 있다.
- sex 열은 male과 female , 남성과 여성이 몇명인지 확인할 수 있고, male이 더 많은 것을 알 수 있다.
- cabin 열은 [대문자 + 숫자]의 값으로 되어 있는데 이에 대하여 숫자를 무의미하다 판단하였기 때문에 맨 앞글자에 해당하는 대문자만 추출해줄 것이다.
- embarked에는 S, C, Q, N이 존재하고, 이는 중간 정착 항구가 S가 가장 많은 것을 알 수 있다.

5. 문자열 변수 처리
- Cabin열의 맨 처음 대문자만 추출해주기 위해서 str[:1]로 지정해주었다.
- str은 문자열을 의미하고, [처음, 지정한 자리수 -1]안에 추출하고 싶은 범위를 지정해주면 되는데, 파이썬은 맨 첫번째 글자가 0이기 때문에 ":" -> "처음부터" 라는 의미 , "1"은 두번째 자리를 의미하고, 결론적으로 "처음부터 두번째 자리 -1 자리수"를 추출해라는 의미이다.

6. 데이터 EDA
- seaborn 모듈을 사용하여 성별에 따른 생존자 비율을 막대그래프(barplot)로 그려보았다.
- 남성보다는 여성이 더 많이 생존한 것을 확인 할 수 있다.

- 티켓의 선실 등급에 따른 생존자를 성별로 구분해서 그려준 막대그래프 이다.
- 결과적으로 1등급 선설에 있는 사람들이 가장 많이 생존했고, 공통적으로 여성이 더 많이 생존한 것도 알 수 있다.

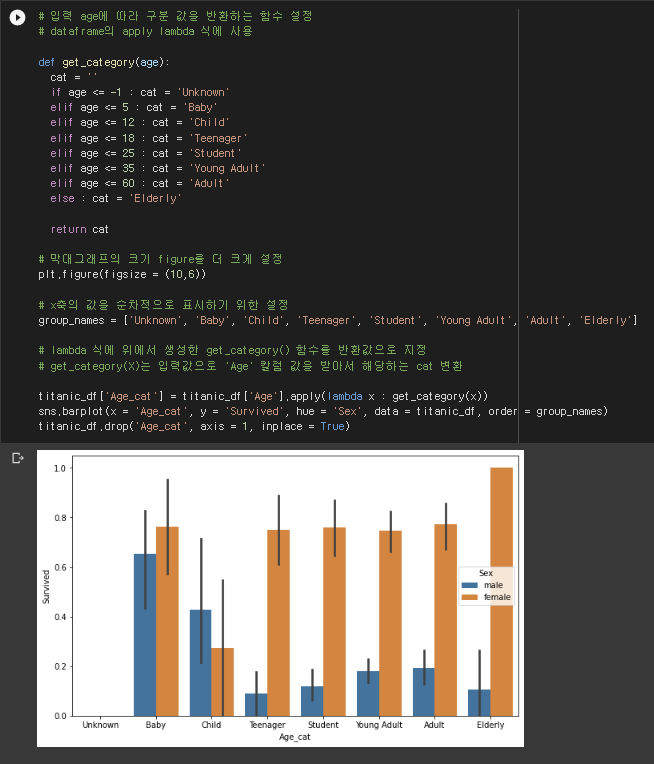
- 나이에 따른 생존자를 알아보기 위하여 총 8가지 종류로 구분시켜주는 함수를 지정했다.
- 막대그래프의 크기를 조금 키워주고, group_names 변수에 x축에 표시하고 싶은 변수 명들을 지정해주었다.
- apply(lambda x) 함수를 사용하여 앞서 만든 get_category 함수를 age 변수에 입력시켜주고 "Age_cat" 라는 새로운 변수를 데이터 프레임에 지정해주었다.
- 새롭게 만들어준 Age_cat 변수는 x축으로, Survived 변수를 y축으로 지정해준다음, hue에 sex를 입력하여 범례를 지정해주었다.
- 또, order이라는 정렬 함수에 앞서 만들어준 group_names를 지정해주어 x 축에 원하는 순서대로 값들이 보이도록 해주었다.
- 결론적으로 남성은 1살 ~ 5살 까지의 승객들이 가장 많이 생존하였고, 여성은 60살 이상의 승객들이 가장 많이 생존한 것을 알 수 있다.
7. 라벨 인코딩
- 다시 되짚어보면 sex, cabin, embarked, 총 3가지 열이 문자열 변수인 것을 확인할 수 있었다.
- 모델 알고리즘에 입력데이터로 사용하기 위해서는 모든 값들을 수치로 변환시켜주어야 하기 때문에 인코딩을 진행하였다.
- 사이킷런의 labelencoder를 불러와주고, encode_features() 함수를 새롭게 만들어주었다.
- encode_features 함수에 fit()과 transform()를 이용하여 cabin, sex, embarked 변수를 인코딩하는 코드를 삽입했다.
- 만들어진 encode_features 함수에 타이타닉 데이터 프레임을 지정하여 문자열 변수를 수치형으로 바꾸어 주었다.

- 밑의 코드는 앞서 진행한 것을 함수로 보기 쉽게 정리한 것이다.
- 다만 조금 다른점은 분석하는데 중요한 역할을 하지 않을 것으로 판단된 Name, PassengerID, Ticket 열을 제거해주는 코드를 삽입해주었다.

8. 학습 데이터와 테스트 데이터 분리
- 학습 데이터 셋을 의미하는 X_titanic_df에는 예측해야 하는 열인 Survived를 제거해주었다.
- 테스트 데이터 셋을 의미하는 y_titanic_df에는 예측하고 싶은 열인 Survived만 추출해주어 데이터 프레임으로 만들어주었다.
- 사이킷런의 train_test_split 모듈을 이용하여 학습 데이터 셋과 테스트 데이터 셋을 분리해주었다.

9. 모델링
- 일단 사용한 모델을 총 3가지로, 의사결정나무, 랜덤포레스트, 로지스틱 회귀를 사용했고, 모델 성능은 accuracy로 확인했다.
- 각각 dt_clf, rf_clf, lr_clf 로 모델을 만들어주는데, lr_clf의 생성 인자로 입력된 solver = 'libliner'는 로지스틱 회귀의 최적화 알고리즘을 설정한 것이다. 일반적으로 로지스틱 회귀에서 libliner 알고리즘이 가장 성능이 좋다.
- fit() 함수로 학습 데이터를 훈련시키고 predict 함수로 테스트 데이터로 예측한 뒤에 예측한 것과 실제 테스트 데이터 셋과 비교한 성능을 확인한 결과 로지스틱 회귀의 정확도가 가장 높게 나온 것을 알 수 있었다.

+) 교차검증
- 학습데이터와 테스트 데이터를 분리해줄 때 train_test_split도 있지만 교차검증도 있기 때문에 교차검증도 함께 진행시켜 보았다.
- KFold 교차검증을 진행해주었고, folds의 갯수는 5개로 지정했다.
- for 함수로 반복문을 짜고, train과 test 함수를 입력하고 예측해준 다음 각각 교차검증을 진행한 정확도를 구해주고, 평균적인 정확도도 구해주었다.

- 앞서 함수를 짜서 사용하는 kfold 교차검증 보다는 cross_val_score 를 이용하여 교차검증을 수행하면 조금 더 쉽게 구현할 수 있다.
- 최종적으로 두 개의 정확도가 차이가 나는 것은 cross_val_score이 자동적으로 stratifiedKFold로 분할하였기 때문이다.

+) GridSearch
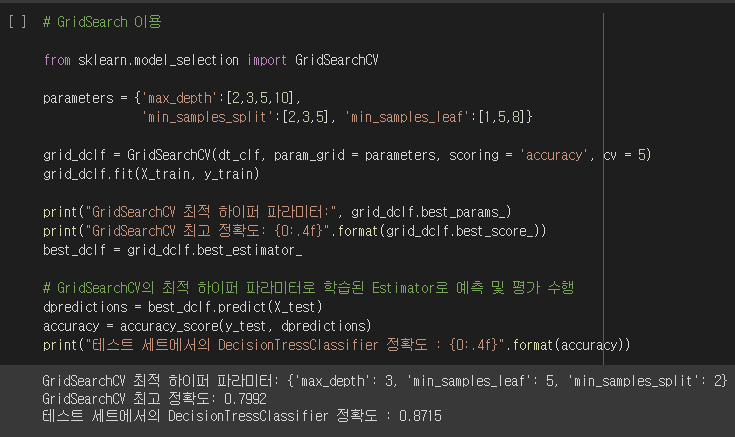
- 앞서 모델로 사용했던 의사결정나무의 정확도를 조금 더 좋게 만들기 위해서 GridSearchCV를 사용해주었다.
- 의사결정 나무의 하이퍼 파라미터 중에서도 max_depth, min_samples_split, min_samples_leaf 를 변경해주면서 가장 좋은 성능을 이끌어내는 하이퍼 파라미터를 찾고 성능을 확인해본 결과 78% 에서 87%로 성능이 확인 된 것을 알 수 있다.
'Data Analysis > Python' 카테고리의 다른 글
| 결정 트리 실습 - 사용자 행동 인식 데이터 세트를 활용하여 (0) | 2023.01.31 |
|---|---|
| 분류_결정트리(DecisonTreeClassifier) (0) | 2023.01.31 |
| 스케일링 및 정규화 (0) | 2023.01.11 |
| 데이터 인코딩 (0) | 2023.01.10 |
| 사이킷런의 model_selection (0) | 2023.01.05 |